#|eval: false
#answer = input("What's your name?")
#answer.strip().title()
#print(f"Hello, {answer}")
# Abbreviated version
#answer = input("What's your name?").strip().title()
#print(f"hello, {answer}")Strings
Basics
- Strings are a sequence of characters
- Think of a string as a list or a tupple

Input
- I’ll start here because inputs required from the user ecwill be treated as a variable regardless of what’s entered
- In other words, if we ask the user to input their name, they might enter numbers instead, so for now let’s just treat input as that a variable assigned whatever the user responds to the input prompt
- What you see in the first chunk is asking the user to enter a name
- Then we strip any spaces from either end of the answer, chained to title() which will capitalize the first letter of each word they input
- Then we format print the response
Indexing
- Each element of the sequence can be accessed using an index with the first character on the left being 0
- Let’s pretend we have a
Name= Michael Jacksonso:Name[0]->N,Name[6]->l

Negative Indexing
- Is when we want to access the string in reverse order, the last character is -1 and counting down as we move towards the beginning of the string
Name[-1]-> n&Name[-6]->a

Slice to Var
- You can bind a string to another var, even part of a string
- Here we slice part of Name and bind it to Mich
Name[0:4] -> Mich&Name[8:12]->Jack
IMPORTANT: 0:4 -> Mich which is only 4 characters, while 0:4 is 5 characters in R. So in R 0:4 would be Micha. Same applies with negative indexing and mid string slicing like [8:12] -> Jack in R it would -> Jacks
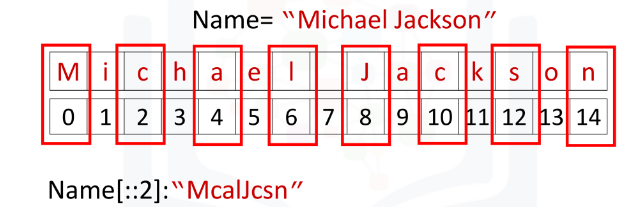
Stride
- We can extract a stride value such as every second variable with ::2 as such:
Name[::2] -> "McalJcsn" - We can incorporate striding and slicing:
Name[0:5:2] -> "Mca"
Len
- We can use the len() to obtain the length of the string
- len(Name) -> 15
# Measure some strings:
words = ['cat', 'window', 'defenestrate']
for w in words:
print(w, len(w))cat 3
window 6
defenestrate 12Concatenate
- Combine strings together end to beginning using
+ +does not add a separator between the concatenated strings
Split
- Splits string into a list based on a delimiter
- Default separator is white space
- For example:
"$123,456,789"if we split using","we end up with"$123" "456" "789"
my_string=" Hello, there. What's up, goose "
split_text = my_string.split(",")
split_text[' Hello', " there. What's up", ' goose ']We can expand on the input and split:
- Let’s suppose the input we want is first , last name
- So answer from input above will have two words: first and last separated by space
- So answer = Santa Claus is what the user inputs and it is assigned to answer
- Now we can use split the answer by a separator and assign the left string to first and second string to last using
- first, last = name.split(” “)
- Now we can choose one or both variable to print
#|eval: false
# remember name = input("What's your name?").strip().title()
# first, last = name.split(" ")
# print(f"Hello, {first}")Strip
- Removes leading and trailing whitespaces ONLY
- Does not remove any spaces inside the string
stripped = my_string.strip()
print(stripped)Hello, there. What's up, goose- Here is another example
blah = " this is crazy "
blah.strip()'this is crazy'#If we want to Title it we can chain commands
blah.strip().title()'This Is Crazy'Replicate
- We can replicate a string by using the multiplication like this
Name * 3 -> "Michael Jackson Michael Jackson Michael Jackson"
Immutable
- Strings are immutable, in other words you cannot change the value of a string
Escape Sequences
\are meant to proceed escape sequences- Escape sequences are strings that are difficult to interpert on their own unless preceeded by the
\ print("Michael Jacksion \n is over there")here means a new line- epresents a tab
- To use a \ in a string use the \\
Raw Strings
Raw strings are a powerful tool for handling textual data, especially when dealing with escape characters.
By prefixing a string literal with the letter ‘r’, Python treats the string as raw, meaning it interprets backslashes as literal characters rather than escape sequences.
Here is an example without the use of
r:In the regular string regular_string variable, the backslashes (\n) are interpreted as escape sequences. Therefore, \n represents a newline character, which would lead to an incorrect file path representation.
regular_string = "C:\new_folder\file.txt"
print("Regular String:", regular_string)Regular String: C:
ew_folder
ile.txt- Here is the same using the raw string method
- In the raw string raw_string, the backslashes are treated as literal characters.
- This means that \n is not interpreted as a newline character, but rather as two separate characters, ’’ and ‘n’. Consequently, the file path is represented exactly as it appears.
raw_string = r"C:\new_folder\file.txt"
print("Raw String:", raw_string)Raw String: C:\new_folder\file.txtMethod
Upper
- Method is an operation performed on a string such as
upper() - new_name = Name.upper()
Lower
- new_name = Name.lower()
- Here is an example, ignore the meaning of the function
_init_
# Constructor method
def __init__(self, text):
lowertext = text.lower()
cleantext = lowertext.replace('.','').replace('!','').replace('?','').replace(',','')
self.fmtText = cleantextTitle
- What if we want to capitalize the first letter of each word, use title
line = "hello gringo. did you see santa"
line.title()'Hello Gringo. Did You See Santa'Replace
replace(old, new, count)will do exactly that- count is for how many occurrences of the old value you want to replace, default is all occurrences if you omit
new_name = Name.replace('Michael', 'Janet')-> new_name:"Janet Jackson"
Name = 'Michael Jackson'
new_name = Name.replace('Michael', 'Janet')
new_name'Janet Jackson'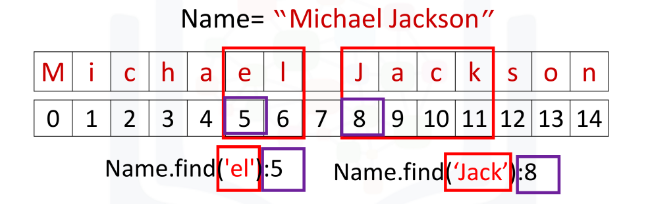
Replace Multiple
- If you have multiple sequences to replace you can use one cumulative statement
- Here you can see that we can string
.replace()together
cleantext = texttoedit.replace('.','').replace('!','').replace('?','').replace(',','')Find
find(substring)will search the given string for the substring and returns the index of the first character of the substring found in the given stringName.find('el') -> 5e in el was encountered at the 5th index - remember the fist character index is 0 so the 5th would make it the sixth character in NameName.find('Jack') -> 8which would mean J is the ninth character in Name
Count Occurrence
- If you want to count the occurrence of a specific string, or
- Count unique appearance of words
- Please refer to this example project which is found in Projects page.
RegEx
In Python, RegEx (short for Regular Expression) is a tool for matching and handling strings.
This RegEx module provides several functions for working with regular expressions, including search, split, findall, and sub.
Python provides a built-in module called re, which allows you to work with regular expressions. First, import the re module
import reSearch
The search() function searches for specified patterns within a string.
- Here is an example that explains how to use the search() function to search for the word “Jackson” in the string “Michael Jackson is the best”.
s1 = "Michael Jackson is the best"
# Define the pattern to search for
pattern = r"Jackson"
# Use the search() function to search for the pattern in the string
result = re.search(pattern, s1)
# Check if a match was found
if result:
print("Match found!")
else:
print("Match not found.")Match found!Regular expressions (RegEx) are patterns used to match and manipulate strings of text. There are several special sequences in RegEx that can be used to match specific characters or patterns.
| Special Sequence | Meaning | Example |
|---|---|---|
| \d | Matches any digit character (0-9) | “123” matches “\d\d\d” |
| \D | Matches any non-digit character | “hello” matches “\D\D\D\D\D” |
| \w | Matches any word character (a-z, A-Z, 0-9, and _) | “hello_world” matches “\w\w\w\w\w\w\w\w\w\w\w” |
| \W | Matches any non-word character | “@#$%” matches “\W\W\W\W” |
| \s | Matches any whitespace character (space, tab, newline, etc.) | “hello world” matches “\w\w\w\w\w\s\w\w\w\w\w” |
| \S | Matches any non-whitespace character | “hello_world” matches “\S\S\S\S\S\S\S\S\S” |
| \b | Matches the boundary between a word character and a non-word character | “cat” matches “\bcat\b” in “The cat sat on the mat” |
| \B | Matches any position that is not a word boundary | “cat” matches “\Bcat\B” in “category” but not in “The cat sat on the mat” |
d
- A simple example of using the
\dspecial sequence in a regular expression pattern - The regular expression pattern is defined as r”\d\d\d\d\d\d\d\d\d\d”, which uses the \d special sequence to match any digit character (0-9)
- and the \d sequence is repeated ten times to match ten consecutive digits
pattern = r"\d\d\d\d\d\d\d\d\d\d" # Matches any ten consecutive digits
text = "My Phone number is 1234567890"
match = re.search(pattern, text)
if match:
print("Phone number found:", match.group())
else:
print("No match")Phone number found: 1234567890w
- A simple example of using the
\Wspecial sequence in a regular expression pattern - The regular expression pattern is defined as r”\W”, which uses the \W special sequence to match any character that is not a word character (a-z, A-Z, 0-9, or _)
- The string we’re searching for matches in is “Hello, world!”
findall
The findall() function finds all occurrences of a specified pattern within a string.
import re
s2 = "Michael Jackson was a singer and known as the 'King of Pop'"
# Use the findall() function to find all occurrences of the "as" in the string
re.findall("as",s2)['as', 'as']# Print out the list of matched words
# Note was a singer a s is countedsplit
A regular expression’s split() function splits a string into an array of substrings based on a specified pattern.
# Use the split function to split the string by the "\s"
re.split('\s', s2)['Michael', 'Jackson', 'was', 'a', 'singer', 'and', 'known', 'as', 'the', "'King", 'of', "Pop'"]
# The split_array contains all the substrings, split by whitespace characterssub
The sub function of a regular expression in Python is used to replace all occurrences of a pattern in a string with a specified replacement.
# Define the regular expression pattern to search for
pattern = r"King of Pop"
# Define the replacement string
replacement = "legend"
# Use the sub function to replace the pattern with the replacement string
new_string = re.sub(pattern, replacement, s2, flags=re.IGNORECASE)
# The new_string contains the original string with the pattern replaced by the replacement string
print(new_string)Michael Jackson was a singer and known as the 'legend'Formatting Strings
f-string - Interpolation
Format strings are a way to inject variables into a string in Python. They are used to format strings and produce more human-readable outputs. There are several ways to format strings in Python.
Introduced in Python 3.6, f-strings are a new way to format strings in Python. They are prefixed with ‘f’ and use curly braces {} to enclose the variables that will be formatted.
name = "John"
age = 30
print(f"My name is {name} and I am {age} years old.")My name is John and I am 30 years old.- F-strings are also able to evaluate expressions inside the curly braces
x = 10
y = 20
print(f"The sum of x and y is {x+y}.")The sum of x and y is 30.str.format
- Use curly braces {} as placeholders for variables which are passed as arguments in the format() method.
name = "John"
age = 50
print("My name is {} and I am {} years old.".format(name, age))My name is John and I am 50 years old.% operator
- This is one of the oldest ways to format strings in Python. It uses the % operator to replace variables in the string.
name = "Johnathan"
age = 30
print("My name is %s and I am %d years old." % (name, age))My name is Johnathan and I am 30 years old.