# Let's create a tuple
Ratings = (1,2,3,4,5)Indexing
Lists & Tuples
Tuple
Tuples: an ordered sequence within parenthese: tuple = (‘string’, flot, int)
- Written as comma-separated elements within parentheses
- All 3 types can be contained in a tuple
- We can concatenate tuples
- Each element can be accessed via an index with the first element assigned to index [0]
- As before, negative index can be used with the last element being [-1]
- Immutable: means you cannot change them, in other words I cannot change an element inside of a tuple
- If we set Ratings1 = Ratings
- Ratings1 does not containRatings but references it
- we cannot change a tuple: Ratings[2] = 7 cannot be done
# Access elements in the tuple with indexing
Ratings[3]4Ratings[-1]5# Let's set the var Ratings1=Ratings
Ratings1 = Ratings# Access elements in the new tuple
Ratings1[3]4Ratings[-1]5- What happens if we change Ratings
# Change the original tuple
Ratings = (12,43,59,598,8876)
# What happens to Ratings1
Ratings1[3]4- As you can see Ratings1 still references the original Ratings
- What if we assign it again after the change has been made, let’s see
- Well now you can see that it references the new Ratings
Ratings1 = Ratings
Ratings1[3]598Slicing
- As with any indexing slicing is applicable along with ranges
Ratings[0:2](12, 43)Ratings[:2](12, 43)Sorting
sorted does what it sounds like, it sorts
tup = (10,9,6,5,10,8,9,6,2,11.5)
sortedtup = sorted(tup)
sortedtup[2, 5, 6, 6, 8, 9, 9, 10, 10, 11.5]Nesting
- Tuples can be nested inside another
- Same indexing convention applies
nt = (1,6,("jack", "cheese"),('fries',3),(45,"turkey",(875,90.45)))
nt[4](45, 'turkey', (875, 90.45))nt[4][1]'turkey'nt[4][2](875, 90.45)nt[4][2][1]90.45List

List is an ordered sequence within brackets [], lst = [ “string”,4,56,78.4,“another”]
lst = [ "string",4,56,78.4,"another"]
lst['string', 4, 56, 78.4, 'another']Length
- We can get the length of the list
len(lst)5- We can extract and print any element using indexing
print('this is the 3rd element of the list:\nls:',lst[2])this is the 3rd element of the list:
ls: 56- Differ from tuples in lists are mutable
- Lists can be nested within a list as well: lst = [2,4,[“hello”,5,4],6,90.5]
- Tuples and other data structures can be nested within a list: blah=[2,4,[“hello”,5], 5, (‘tuple’,5),98.5]
- Of course sorting and indexing is applicable as well
- Can be concatenated
- Since lists are mutable we can change them
Extend
- We can add to a list by using a
method extend() - methods are accessed with the use of
.methodname() - it will concatenate the new list to the existing list
- This point is important because it will extend the old list by AS MANY NEW index position, the new list contains
- Here in the example below we are extending by 2 NEW elements in the new list
lst = [ "string",4,56,78.4,"another"]# To extend our lst we just
lst.extend(["who do",100.4])
lst['string', 4, 56, 78.4, 'another', 'who do', 100.4]len(lst)7Append
- Don’t confuse
.append()with.extend()even though they both add to the old list - extend() concatenates the new list to the old list by adding the list as one element at a time, therefore increasing the previous lists index by number of elements in the new list hereby increasing the index positions by the total number of elements in the new list
- append() will take the whole new list and append it, add it to the end of the old list just adding one index position/ one element to the original number of index position in the original list
- So as you see below the entire new list is appended to the end of the original list unlike extend which breaks down the newlist by elements and adds each element to the original list
lt = [ "string",4,56,78.4,"another"]
lt['string', 4, 56, 78.4, 'another']lt.append(["who do",100.4])
lt['string', 4, 56, 78.4, 'another', ['who do', 100.4]]len(lt)6Edit
- List are mutable so we can change elements within a list
lt[0] = "santa"
print(lt)['santa', 4, 56, 78.4, 'another', ['who do', 100.4]]Delete
- We can delete an element in a list
del(lt[1])
lt['santa', 56, 78.4, 'another', ['who do', 100.4]]Split
- We already covered this in strings
- Converting strings to list can be done using the
.split()method - If you remember the default separator for
.split()is space
st = "hard rock"
st.split()['hard', 'rock']- If we have a string separated by “:” we specify it
st = "ab:who:goes :1:2"
st.split(":")['ab', 'who', 'goes ', '1', '2']Alias
Contrary to Clone & Copy, if we change the values in the original list, the alias list will automatically match the edited original list
- We assign a list to a var
A = st - That’s known as aliasing, now we have both A and st referencing the same list
- Remember with tuples, if we change the original tuple the assigned tuple value will not be affected until we reassign the changed tuple
- With lists that doesn’t apply:
- If we assign A = st
- We change the values in st
- Values in A will automatically change
- Here is an example
st = [ "string",4,56,78.4,"another"]
A = st
A['string', 4, 56, 78.4, 'another']- Let’s change original list: st
- Notice how the assigned var A will change automatically
st[2] = 1000.12
A ['string', 4, 1000.12, 78.4, 'another']Clone
- We can clone a list by using [:]
st = [ "string",4,56,78.4,"another"]
B = st[:]
B['string', 4, 56, 78.4, 'another']- Unlike Aliasing, changing the original list will not affect the cloned list
- Let’s change the original list: st
- Notice how B does not change unless we reassign it if we so choose to
st[3] = 1
B['string', 4, 56, 78.4, 'another']# While the original list st has changed
st['string', 4, 56, 1, 'another']Copy
- Creates a shallow copy of a list
list.copy() - Similar to
list .clone()the cloned list does not update if original list does
st = [ "string",4,56,78.4,"another"]
C = st.copy()
C['string', 4, 56, 78.4, 'another']- Let’s edit st and see what happens to C
st[3] = 1
C['string', 4, 56, 78.4, 'another']Count
- Counts the number of occurrences of a specific element in a list
list.count(object)
lst = [ "string",4,56,78.4,"another","4",44]
lst.count(4)1lst.count("r")0Insert
list.insert(index,element)does what it sounds like, inserts an element in a specified position
n_lst = [ "string",4,56,78.4,"another","4",44]
n_lst.insert(3,7)
print(n_lst)['string', 4, 56, 7, 78.4, 'another', '4', 44]Pop
list.pop(index)extracts, removes and returns the element at the index position- defaults to last element if no argument is provided
n_lst.pop()
n_lst
# As you see in the output, it extracts the element and returns it
# since we requested python to print the list it did that as well['string', 4, 56, 7, 78.4, 'another', '4']n_lst.pop(1)
# As you see it extracted and returned the element at [1]4n_lst
# If you look at the list, the element we popped(1) is no longer in the list['string', 56, 7, 78.4, 'another', '4']Remove
list.remove()removes the first occurrence of the specified value
a = [1,4,5,9,4,12,6,9]
a.remove(4)
a[1, 5, 9, 4, 12, 6, 9]Reverse
list.reverse()does what it sounds like, reverses the order
a = [1,4,5,9,4,12,6,9]
a.reverse()
a[9, 6, 12, 4, 9, 5, 4, 1]Slicing
- NOTE: range applies here. As we explained in For loop, range() is same as [x:y], it is always the difference between x & y not up to and including y
- Already covered many times we can extract a slice from
- a[1:4] > index 1 to index 3 NOT 4, because 4-1=3 so we’ll extract a[1], a[2], a[3] that’s it THREE elements
- a[:3] > up to index 3 which would gives us a range of: 3-0=3, so we’ll extract a[0],a[1],a[2] THREE elements
- a[3:] > elements from index 3 to the end
- a[::2] > extracts every second element
a = [1,2,3,4,5]
a[1:4][2, 3, 4]a[:3][1, 2, 3]a[3:][4, 5]a[::2][1, 3, 5]Sorted
- sorted() sorts the list in ascending order but
- retains the original values of the list intact
a = [1,6,2,3,4,5]
sorted(a)[1, 2, 3, 4, 5, 6]- Look at the original list after using
sorted()
a[1, 6, 2, 3, 4, 5]Sort
- list.sort() defaults to ascending order
- list.sort(reverse = True) will sort in descending order
- Unlike
sorted(),.sort()will alter the original list value
a = [1,6,2,3,4,5]
a.sort()
a[1, 2, 3, 4, 5, 6]a = [1,6,2,3,4,5]
a.sort(reverse = True)
a[6, 5, 4, 3, 2, 1]Dictionary
Dictionaries are used to store data values in key:values pairs
- It is ordered
- changeable
- keys cannot allow duplicates
- here is an example of a dictionary
- keys are viewed as index, so
my_dict["model"]: "Mustang"from the dictionary below - keys are viewed as the first column and values as the second column
Create
- A dictionary is a built-in data type that represents a collection of key-value pairs.
- Dictionaries are enclosed in curly braces `{}`.
Syntax: dict_name = {}- This step can be skipped and we could’ve created a dictionary and assigned values at the same time as we did below
thisdict = {}Assign Values
- Now that we’ve created an empty dictionary we can assign values to it
- The step above can be skipped and we could’ve created a dictionary and assigned values at the same time as we did here below
thisdict = {
"brand": "Ford",
"model": "Mustang",
"year": 1964
}
thisdict{'brand': 'Ford', 'model': 'Mustang', 'year': 1964}Access Values
- Syntax:
Value = dict_name["key_name"] - To extract a value from the dictionary you just set the var to the key you wish to extract the value for
- In this example below, we want to extract the value matched to key model
value1 = thisdict["model"]value2 = thisdict["year"]Add or Edit
- If we use a key that already exists then python will update the paired value with the key we used
- If the key does not exist, one will be created
- In the example below we’ll do both
- As you can see below:
- the key “brand” was updated to “Chevy”
- the new key “size” was added and matched with a value of “4 door”
thisdict["brand"] = "Chevy"
thisdict["size"] = "4 door"
thisdict{'brand': 'Chevy', 'model': 'Mustang', 'year': 1964, 'size': '4 door'}Clear
- The `clear()` method empties the dictionary, removing all key-value pairs within it.
- After this operation, the dictionary is still accessible and can be used further.
- Syntax:
dict_name.clear()
Copy
- Creates a shallow copy of the dictionary.
- The new dictionary contains the same key-value pairs as the original, but they remain distinct objects in memory
- Meaning if the original dictionary is edited the copy will not change (unless you recopy it)
Del
- Syntax:
del dict_name[key]
del thisdict["size"]Keys
- Retrieves all keys from dictionary and converts them into a list.
- This is useful if you wish to process or iterate over the list of keys using the list method
- Syntax:
keys_list = list(dict_name.keys())
keys_list = list(thisdict.keys())
keys_list['brand', 'model', 'year', 'size']Values
- Extracts all values from dictionary and converts them into a list
- Similar to Keys above
- Syntax:
values_list = list(dict_name.values())
values_list = list(thisdict.values())
values_list['Chevy', 'Mustang', 1964, '4 door']Items
- Extracts all key-value pairs and converts them into a list of tuples
- Each tuple consists of a key and its corresponding value
- Syntax:
listofitems = list(dict_name.items())
items_list = list(thisdict.items())
items_list[('brand', 'Chevy'), ('model', 'Mustang'), ('year', 1964), ('size', '4 door')]Key Existence
- You can check if a certain key exists in the dictionary
- Syntax: use an
if "model" in thisdict:
print("model is in the dictionary")model is in the dictionaryUpdate
- Merges the provided dictionary into the existing dictionary
- Adding if didn’t exist or updating key-value pairs
- Syntax:
dict_name.update({key:value}) - Here below we’ll one that already exists and one new one but only one set can be done at once
thisdict.update({"Color":"Blue"})
thisdict.update({"size":"4 doors"})
thisdict{'brand': 'Chevy',
'model': 'Mustang',
'year': 1964,
'size': '4 doors',
'Color': 'Blue'}[1,2,3]+[1,1,1][1, 2, 3, 1, 1, 1]a=[1]
a.append([2,3,4,5])
len(a)2Convert List to Dict
- Here is an example of converting a list to a dict
- More can be found at Projects - Count Words - Dict page
- The example below shows how to loop through a list and create keys and values
- The function happens to count the occurrence of each word in the string
# Count words in a String using Dictionary
# Define the function
def freq(string):
#step1: A list variable is declared and initialized to an empty list.
words = []
#step2: Break the string into list of words
words = string.split() # or string.lower().split()
#step3: Declare a dictionary
Dict = {}
#step4: Use for loop to iterate words and values to the dictionary
for key in words:
Dict[key] = words.count(key)
#step5: Print the dictionary
print("The Frequency of words is:",Dict)
# Call the function and pass string in it
freq("Mary had a little lamb Little lamb, little lamb Mary had a little lamb.Its fleece was white as snow And everywhere that Mary went Mary went, Mary went \
Everywhere that Mary went The lamb was sure to go")The Frequency of words is: {'Mary': 6, 'had': 2, 'a': 2, 'little': 3, 'lamb': 3, 'Little': 1, 'lamb,': 1, 'lamb.Its': 1, 'fleece': 1, 'was': 2, 'white': 1, 'as': 1, 'snow': 1, 'And': 1, 'everywhere': 1, 'that': 2, 'went': 3, 'went,': 1, 'Everywhere': 1, 'The': 1, 'sure': 1, 'to': 1, 'go': 1}Convert DF to Dict Method 1
- Here we’ll go through an example of reading a CSV file into a df then converting the df to a dictionary.
- The entire example is detailed in Bank SQLite3_BS project
def get_exchange_rate(filename):
exchange_df = pd.read_csv(filename)
df_dict = exchange_df.set_index('Currency')['Rate'.to_dict()]
return df_dictConvert DF to Dict Method 2
- Here we’ll go through an example of reading a CSV file into a df then converting the df to a dictionary.
- The entire example is detailed in Bank SQLite3_BS project
# This loop is just to print the key:value pairs so we can verify later
for key in rate:
print(key, rate[key])
Can use list.keys
# another way to extract values
x = 0
for key in rate:
rate[key] = exchange_df.iloc[x,0]
rate[key] = exchange_df.iloc[x,1]
x = x + 1
rateSets
- A set is a unique collection of objects in Python.
- You can denote a set with a pair of curly brackets {}.
- Python will automatically remove duplicate items
Create from Scratch
- You can manually create a set by entering all the information
set1 = {"pop", "rock", "soul", "hard rock", "rock", "R&B", "rock", "disco"}
set1{'R&B', 'disco', 'hard rock', 'pop', 'rock', 'soul'}Convert from List
- You can create one from an existing list with
set(existing_list)command
existing_list = [ "Michael Jackson", "Thriller", 1982, "00:42:19", \
"Pop, Rock, R&B", 46.0, 65, "30-Nov-82", None, 10.0]
set_existing = set(existing_list)
set_existing{'00:42:19',
10.0,
1982,
'30-Nov-82',
46.0,
65,
'Michael Jackson',
None,
'Pop, Rock, R&B',
'Thriller'}new_set = set(["pop", "pop", "rock", "folk rock", "hard rock", "soul", \
"progressive rock", "soft rock", "R&B", "disco"])
new_set{'R&B',
'disco',
'folk rock',
'hard rock',
'pop',
'progressive rock',
'rock',
'soft rock',
'soul'}Add
set.add(element)will add and element to the set- Python will not allow adding a duplicate to a set
A = set(["Tacos", "Chicken", "Pizza"])
A.add("Wings")
A{'Chicken', 'Pizza', 'Tacos', 'Wings'}- Let’s add another set of Pizza
A.add("Pizza")
A
# As you can see Python will not allow a duplicate{'Chicken', 'Pizza', 'Tacos', 'Wings'}Remove
- Syntax: set.remove(element)
A.remove("Wings")
A{'Chicken', 'Pizza', 'Tacos'}Element Existence
- We can check if an element is in the set with
- Syntax:
element in set
"Musrhrooms" in AFalseDifference in Sets
- We can check the difference between two sets as well as
- The symmetric difference
- The intersection and
- The union of sets
- Let’s create two sets
set1 = set(["Thriller", 'AC/DC', 'Back in Black'])
set2 = set([ "AC/DC", "Back in Black", "The Dark Side of the Moon"])
set1, set2({'AC/DC', 'Back in Black', 'Thriller'},
{'AC/DC', 'Back in Black', 'The Dark Side of the Moon'})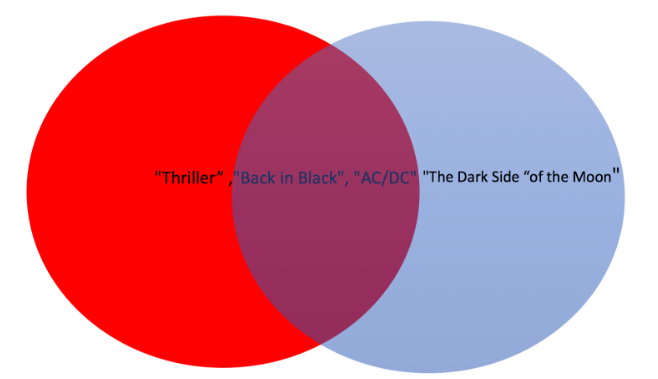
Intersect
- What belongs to both
intersect = set1 & set2
intersect{'AC/DC', 'Back in Black'}- We can also use the intersection method
set1.intersection(set2){'AC/DC', 'Back in Black'}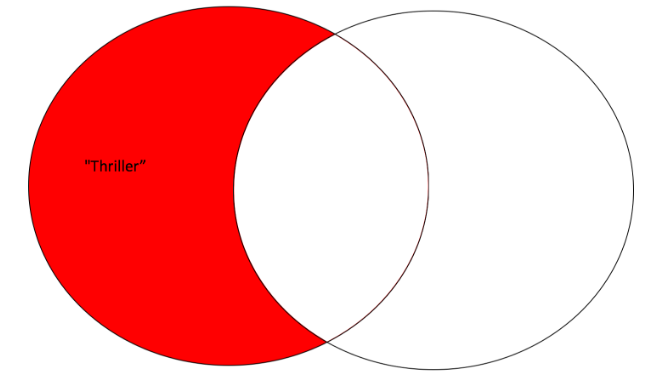
Left Contained
- What belongs to the left one here:set1 and
- doesn’t belong to the right one: set2
- so exclusively in left set: set1
- Kinda like Left Outer
- Syntax:
left_set.difference(right_set)
set1.difference(set2){'Thriller'}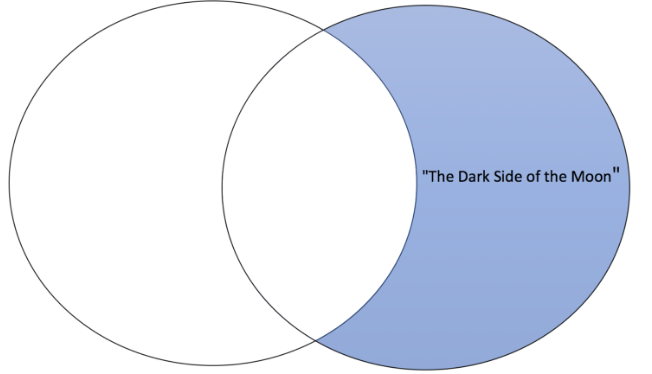
Right Contained
- What belongs to the right set: set 2 and
- not part of set1
- Similar to Right Outer
set2.difference(set1){'The Dark Side of the Moon'}Union
- Is the combined both sets
set1.union(set2){'AC/DC', 'Back in Black', 'The Dark Side of the Moon', 'Thriller'}Superset & Subset
- You can check if a set is a superset or subset of another
- Superset engulfs a subset
- Subset is a part of a superset
# Check if superset
set(set1).issuperset(set2)False# Check if subset
set(set2).issubset(set1)False- Here are two examples where both superset and subset are true
# Check if subset
set({"Back in Black", "AC/DC"}).issubset(set1) True# Check if superset
set1.issuperset({"Back in Black", "AC/DC"}) TrueA=((11,12),[21,22])
A[0][1]12