library(reticulate)
py_install("numpy")
py_install("pandas")
py_install("pyodide.http")
py_install("seaborn")
py_install("openpyxl")I/O
import pandas as pd
import numpy as np
# pip install pyodide.http
# pip install seaborn
# pip install openpyxl
#install(['seaborn','xml','openpyxl'])
# from pyodide.http import pyfetch.TXT file .READ
This first section we’ll focus on OPEN
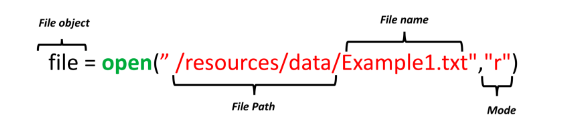
OPEN ‘r’
- Reading text files involves extracting and processing the data stored within them. Text files can have various structures, and how you read them depends on their format.
- Here’s a general guide on reading text files with different structures.
- Plain text files contain unformatted text without any specific structure
- You can read plain text files line by line or load all the content into your memory
- Syntax:
# Open file in read ('r') mode
material = open('sourcefile','r')
with OPEN ‘r’
- It is always good to close the file after using Open, and it gets tedious to always type the close() command, we can avoid all that using
with()which automatically closes the file afterread()
# Use with() which automatically closes the file after reading
with open(sourcefile, 'r') as file:.READ
.read() Reads the content of a file into a variable as a string separated by
# Use with() which automatically closes the file after reading
with open(sourcefile, 'r') as file:
# Use read method to read the entire file
material = file.read()
# Now you can manipulate the content that's stored in material
print(material).READLINES
.readlines() reads all the lines line by line and save to a list
with open(sourcefile, 'r') as file:
listoflines = file.readlines()- Then you can print any line by index
# Print first line
listoflines[0].READLINE
.readline() outputs every line as an element in a list. Reads one line ONLY
- material[0] is the first element of the list and corresponds to the first line and so on
- every time you call the method readline() it will read the next line and store its value in the next element of the list material[x]
- Therefore you can use a loop to go through the entire file and extract each line to an element in the list material
with open(sourcefile, 'r') as file:
line1 = file.readline() # reads the first line
line2 = file.readline() # reads the second lineExtract Line
- You can work with each line you read, for example
- Print the lines that contain a certain word
with open(sourcefile, 'r') as file:
line1 = file.readline() # reads the first line
line2 = file.readline() # reads the second line
print(line1) # Prints the first line
if 'santa' in line 2:
print("Santa is in the house!?")All Lines For Loop
- Loop through the file and print lines
with open(sourcefile, 'r') as file:
i = 0;
for line in file:
print("Iteration", str(i),": ", line)
i = i+1- Use a loop to read lines until no more lines are left
- Like reading the entire book line by line
All Lines While Loop
with open(sourcefile, 'r') as file:
while True:
line = file.readline()
if not line:
break # stop when all the lines have been readYou can specify the number of chars to read
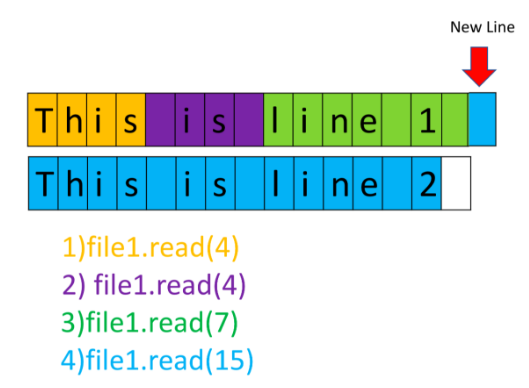
Extract Chars in Line
- We can limit the number of characters to read from a line in the file by sending an argument in
readline() - To read the first 4 chars we use:
material = sourcefile.readline(4) - If we call 4 chars of a 15 char line then the next time we call the method it will read start with char 5 and count out
It reads the specified number of characters from the current position. So if we read the first 5 chars, the next read() will start where it left off, with the 6th character
with open(sourcefile, 'r') as file:
# Use read method to read the first 5 characters
material = file.readline(5)SEEK Chars
- To read a specific character from a specific position in the file you use
seek() seek()moves the cursor (file pointer) to a particular position or char- The position is in bytes so you need to know the byte offset of the desired character
- To read the 11th character we use index 10 (it is 0-based index)
.seek(offset,from)- changes the position by ‘offset’ bytes with respect to ‘from’. From can take the value of 0,1,2 corresponding to beginning, relative to current position and end
with open(sourcefile, 'r') as file:
file.seek(10) # read first 11 chars in file.TXT file .WRITE
with OPEN ‘w’
- Similar to open(.., ‘r’) we change the mode to ‘w’ to write.
- We can also use ‘a’ to append which appends to the existing file and not write over it
- Here you can see the similarities
# Open file in write ('w') mode
list = open('sourcefile','w').WRITE
- Open the file using the write() to save the text file to a list
.write will overwrite existing data in the file
with open(sourcefile, 'w') as writefile:
writefile.write("Write this line1 to file")- We can check to see if it worked using the open read
with open(sourcefile, 'r') as checkfile:
print(checkfile.read()).WRITE Lines
- write multiple lines
- similar to read it works the same way in reverse

with open(sourcefile, 'w') as writefile:
writefile.write("This is line A\n")
writefile.write("this is line B\n")
# note the new line \n at the end of each line
# check the file to see if it worked
with open(sourcefile, 'r') as checkfile:
print(checkfile.read()).WRITE List
- To write a list of lines to a file use a loop
Lines = ["This is line A\n", "This is line B\n", "This is line C\n"]
with open('/sourcefile.txt', 'w') as writefile:
for line in lines:
print("We are about to add this line: ",line)
writefile.write(line).TXT file APPEND
with OPEN ‘a’
Appending to a file just adds to the end of it without affecting the previous content
- Writing to a file erases the existing data
- We just change the mode to ‘a’ and use the write method
with open(sourcefile, 'a') as writefile:
writefile.write("This is line C\n")
writefile.write("this is line D\n")
# note the new line \n at the end of each line
# check the file to see if it worked
with open(sourcefile, 'r') as checkfile:
print(checkfile.read()).TXT file A+
- It is used for appending and reading
with open('/Example2.txt', 'a+') as testwritefile:
print("Initial Location: {}".format(testwritefile.tell()))
data = testwritefile.read()
if (not data): #empty strings return false in python
print('Read nothing')
else:
print(testwritefile.read())
testwritefile.seek(0,0) # move 0 bytes from beginning.
print("\nNew Location : {}".format(testwritefile.tell()))
data = testwritefile.read()
if (not data):
print('Read nothing')
else:
print(data)
print("Location after read: {}".format(testwritefile.tell()) )Other Modes
It’s fairly inefficient to open the file in a or w and then reopening it in r to read any lines. Luckily we can access the file in the following modes:
- r+ : Reading and writing. Cannot truncate the file.
- w+ : Writing and reading. Truncates the file.
- a+ : Appending and Reading. Creates a new file, if none exists
The difference between w+ and r+: Both of these modes allow access to read and write methods however, opening a file in w+ overwrites it and deletes all pre-existing data
Opening the file in w is akin to opening the .txt file, moving your cursor to the beginning of the text file, writing new text and deleting everything that follows.
Manipulate File
.TRUNCATE
To work with a file on existing data, use r+ and a+. When using r+ it is useful to add .truncate() method at the end of your data. This will reduce the file to your data and delete everything that follows
with open('/Example2.txt', 'r+') as testwritefile:
testwritefile.seek(0,0) #write at beginning of file
testwritefile.write("Line 1" + "\n")
testwritefile.write("Line 2" + "\n")
testwritefile.write("Line 3" + "\n")
testwritefile.write("Line 4" + "\n")
testwritefile.write("finished\n")
#Uncomment the line below
testwritefile.truncate()
testwritefile.seek(0,0)
print(testwritefile.read()).TELL
Whereas opening the file in a is similiar to opening the .txt file, moving your cursor to the very end and then adding the new pieces of text.
It is often very useful to know where the ‘cursor’ is in a file and be able to control it. The following methods allow us to do precisely this -
.tell()- returns the current position in bytes.seek()we saw earlier
Copy File to File
You can copy the contents of one file to another by reading from the source file and writing to the destination file
# Open the source file for reading
with open('source.txt', 'r') as source_file:
# Open the destination file for writing
with open('destination.txt', 'w') as destination_file:
# Read lines from the source file and copy them to the destination file
for line in source_file:
destination_file.write(line)
# Destination file is automatically closed when the 'with' block exits
# Source file is automatically closed when the 'with' block exitsFile Modes
More can be found here inI/O using Python.
| Mode | Syntax | Description |
|---|---|---|
| ‘r’ | 'r' |
Read mode. Opens an existing file for reading. Raises an error if the file doesn’t exist. |
| ‘w’ | 'w' |
Write mode. Creates a new file for writing. Overwrites the file if it already exists. |
| ‘a’ | 'a' |
Append mode. Opens a file for appending data. Creates the file if it doesn’t exist. |
| ‘x’ | 'x' |
Exclusive creation mode. Creates a new file for writing but raises an error if the file already exists. |
| ‘rb’ | 'rb' |
Read binary mode. Opens an existing binary file for reading. |
| ‘wb’ | 'wb' |
Write binary mode. Creates a new binary file for writing. |
| ‘ab’ | 'ab' |
Append binary mode. Opens a binary file for appending data. |
| ‘xb’ | 'xb' |
Exclusive binary creation mode. Creates a new binary file for writing but raises an error if it already exists. |
| ‘rt’ | 'rt' |
Read text mode. Opens an existing text file for reading. (Default for text files) |
| ‘wt’ | 'wt' |
Write text mode. Creates a new text file for writing. (Default for text files) |
| ‘at’ | 'at' |
Append text mode. Opens a text file for appending data. (Default for text files) |
| ‘xt’ | 'xt' |
Exclusive text creation mode. Creates a new text file for writing but raises an error if it already exists. |
| ‘r+’ | 'r+' |
Read and write mode. Opens an existing file for both reading and writing. |
| ‘w+’ | 'w+' |
Write and read mode. Creates a new file for reading and writing. Overwrites the file if it already exists. |
| ‘a+’ | 'a+' |
Append and read mode. Opens a file for both appending and reading. Creates the file if it doesn’t exist. |
| ‘x+’ | 'x+' |
Exclusive creation and read/write mode. Creates a new file for reading and writing but raises an error if it already exists. |
PANDAS
.CSV read
Look in Pandas - Intro for more
# Read the CSV file into a DataFrame
file_path = 'D:/yourdataiq/main/datasets/avgpm25.csv'
df = pd.read_csv(file_path)- We can still use the open
- You will notice we used wb mode which is write & byte
from pyodide.http import pyfetch
filename = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%205/data/addresses.csv"
async def download(url, filename):
response = await pyfetch(url)
if response.status == 200:
with open(filename, "wb") as f:
f.write(await response.bytes())
await download(filename, "addresses.csv")
df = pd.read_csv("addresses.csv", header=None)
df.head(5)Write JSON to File
JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write.JSON is built on two structures:
- A collection of name/value pairs. In various languages, this is realized as an object, record, struct, dictionary, hash table, keyed list, or associative array.
- An ordered list of values. In most languages, this is realized as an array, vector, list, or sequence.
- The text in JSON is done through quoted string which contains the values in key-value mappings within { }. It is similar to the dictionary in Python.
Serialization
The act of writing to a JSON file is called serialization.
- To handle the data flow in a file, the JSON library in Python uses the dump() or dumps() function to convert the Python objects into their respective JSON object. This makes it easy to write data to files.
import json
person = {
'first_name' : 'Mark',
'last_name' : 'abc',
'age' : 27,
'address': {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021-3100"
}
}Dump
- json.dump() method can be used for writing to JSON file.
- Syntax: json.dump(dict, file_pointer)
- Parameters:
- dictionary – name of the dictionary which should be converted to JSON object.
- file pointer – pointer of the file opened in write or append mode.
- Parameters:
with open('person.json', 'w') as f: # writing JSON object
json.dump(person, f)Dumps
- json.dumps() that helps in converting a dictionary to a JSON object.
- It takes two parameters:
- dictionary – name of the dictionary which should be converted to JSON object.
- indent – defines the number of units for indentation
# Serializing json
json_object = json.dumps(person, indent = 4)
# Writing to sample.json
with open("sample.json", "w") as outfile:
outfile.write(json_object)219
print(json_object){
"first_name": "Mark",
"last_name": "abc",
"age": 27,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021-3100"
}
}Our python objects are now serialized to the file. For deserialization back to the python object we just use the load() function
Read JSON Files
- Language is similar to a dictionary
- Import json
- open file with the ‘r’ attribute
- Load the file into an object (we’ll use the file we created above)
import json
with open('sample.json','r') as openfile:
json_object = json.load(openfile)
print(json_object)
print(type(json_object))Read XLSX Files
- XLSX is a Microsoft Excel Open XML file format. It is another type of Spreadsheet file format.
- In XLSX data is organized under the cells and columns in a sheet.
import urllib.request
urllib.request.urlretrieve("https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%205/data/file_example_XLSX_10.xlsx", "sample.xlsx")
filename = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%205/data/file_example_XLSX_10.xlsx"
async def download(url, filename):
response = await pyfetch(url)
if response.status == 200:
with open(filename, "wb") as f:
f.write(await response.bytes())
await download(filename, "file_example_XLSX_10.xlsx")
df = pd.read_excel("file_example_XLSX_10.xlsx")READ_XML
We can also read the downloaded xml file using the read_xml function present in the pandas library which returns a Dataframe object.
For more information read the pandas.read_xml documentation.
# Herein xpath we mention the set of xml nodes to be considered for migrating to the dataframe which in this case is details node under employees.
df=pd.read_xml("Sample-employee-XML-file.xml", xpath="/employees/details")Read XML Files
- Pandas does not read this type of file directly but here is how we can parse it
- XML is also known as Extensible Markup Language. As the name suggests, it is a markup language.
- It has certain rules for encoding data. XML file format is a human-readable and machine-readable file format.
- Pandas does not include any methods to read and write XML files.
- Here, we will take a look at how we can use other modules to read data from an XML file, and load it into a Pandas DataFrame.
import pandas as pd
import xml.etree.ElementTree as etree
tree = etree.parse('filename.xml')
root = tree.getroot()
# create column headers
columns = ['Name','Phone',....]
# assign columns to df
df = pd.DataFrame(columns = columns)
# Create a loop to go through the document to collect the necessary data and append to a df
for node in root:
name = node.find('name').text
phonenumber = node.find('phonenumber').text
birthday = node.find('birthday').text
df = df.append(pd.Series([name, phonenumer, birthday], index=columns)..., ignore_index = True)Another Example
# Parse the XML file
tree = etree.parse("Sample-employee-XML-file.xml")
# Get the root of the XML tree
root = tree.getroot()
# Define the columns for the DataFrame
columns = ["firstname", "lastname", "title", "division", "building", "room"]
# Initialize an empty DataFrame
datatframe = pd.DataFrame(columns=columns)
# Iterate through each node in the XML root
for node in root:
# Extract text from each element
firstname = node.find("firstname").text
lastname = node.find("lastname").text
title = node.find("title").text
division = node.find("division").text
building = node.find("building").text
room = node.find("room").text
# Create a DataFrame for the current row
row_df = pd.DataFrame([[firstname, lastname, title, division, building, room]], columns=columns)
# Concatenate with the existing DataFrame
datatframe = pd.concat([datatframe, row_df], ignore_index=True)Write to XML File
The xml.etree.ElementTree module comes built-in with Python. It provides functionality for parsing and creating XML documents. ElementTree represents the XML document as a tree. We can move across the document using nodes which are elements and sub-elements of the XML file.
For more information please read the xml.etree.ElementTree documentation.
import xml.etree.ElementTree as ET
# create the file structure
employee = ET.Element('employee')
details = ET.SubElement(employee, 'details')
first = ET.SubElement(details, 'firstname')
second = ET.SubElement(details, 'lastname')
third = ET.SubElement(details, 'age')
first.text = 'Shiv'
second.text = 'Mishra'
third.text = '23'
# create a new XML file with the results
mydata1 = ET.ElementTree(employee)
# myfile = open("items2.xml", "wb")
# myfile.write(mydata)
with open("new_sample.xml", "wb") as files:
mydata1.write(files)Read HTML Content
The top-level read_html() function can accept an HTML string/file/URL and will parse HTML tables into list of pandas DataFrames. Let’s look at a few examples.
read_html returns a list of DataFrame objects, even if there is only a single table contained in the HTML content.
Scrape Table w Pandas
pd.read_html(url)
- Set url to the path
- Without setting any options
url = "https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list"
pd.read_html(url)[ Bank Name ... Fund Sort ascending
0 The First National Bank of Lindsay ... 10547
1 Republic First Bank dba Republic Bank ... 10546
2 Citizens Bank ... 10545
3 Heartland Tri-State Bank ... 10544
4 First Republic Bank ... 10543
5 Signature Bank ... 10540
6 Silicon Valley Bank ... 10539
7 Almena State Bank ... 10538
8 First City Bank of Florida ... 10537
9 The First State Bank ... 10536
[10 rows x 7 columns]]The drawback is this method ignores many attributes we might want from the page. But if all we needed was the table and what’s in it, this could work. If we need links or other elements then it might be smart to use other methods of scraping the page
Read Binary Files
“Binary” files are any files where the format isn’t made up of readable characters. It contain formatting information that only certain applications or processors can understand. While humans can read text files, binary files must be run on the appropriate software or processor before humans can read them.
Binary files can range from image files like JPEGs or GIFs, audio files like MP3s or binary document formats like Word or PDF.
Let’s see how to read an Image file.
Image Files
- Python supports very powerful tools when it comes to image processing. Let’s see how to process the images using the PIL library.
- PIL is the Python Imaging Library which provides the python interpreter with image editing capabilities.
# importing PIL
from PIL import Image
# Uncomment if running locally
# import urllib.request
# urllib.request.urlretrieve("https://hips.hearstapps.com/hmg-prod.s3.amazonaws.com/images/dog-puppy-on-garden-royalty-free-image-1586966191.jpg", "dog.jpg")
filename = "https://hips.hearstapps.com/hmg-prod.s3.amazonaws.com/images/dog-puppy-on-garden-royalty-free-image-1586966191.jpg"
async def download(url, filename):
response = await pyfetch(url)
if response.status == 200:
with open(filename, "wb") as f:
f.write(await response.bytes())
await download(filename, "./dog.jpg")
# Read image
img = Image.open('./dog.jpg','r')
# Output image
img.show()Save to CSV
- To save a DataFrame to a CSV file, use the to_csv method and specify the filename with a “.csv” extension.
- Pandas provides other functions for saving DataFrames in different formats.
df.to_csv('filename.csv', index = false)Read/Save Other Data Formats
| Data Formate | Read | Save |
|---|---|---|
| csv | pd.read_csv() |
df.to_csv() |
| json | pd.read_json() |
df.to_json() |
| excel | pd.read_excel() |
df.to_excel() |
| hdf | pd.read_hdf() |
df.to_hdf() |
| sql | pd.read_sql() |
df.to_sql() |
| … | … | … |
IO tools
The pandas I/O API is a set of top level reader functions accessed like pandas.read_csv() that generally return a pandas object. The corresponding writer functions are object methods that are accessed like DataFrame.to_csv(). Below is a table containing available readers and writers.
| Format Type | Data Description | Reader | Writer |
|---|---|---|---|
| text | CSV | read_csv | to_csv |
| text | Fixed-Width Text File | read_fwf | |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | LaTeX | Styler.to_latex | |
| text | XML | read_xml | to_xml |
| text | Local clipboard | read_clipboard | to_clipboard |
| binary | MS Excel | read_excel | to_excel |
| binary | OpenDocument | read_excel | |
| binary | HDF5 Format | read_hdf | to_hdf |
| binary | Feather Format | read_feather | to_feather |
| binary | Parquet Format | read_parquet | to_parquet |
| binary | ORC Format | read_orc | to_orc |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | SPSS | read_spss | |
| binary | Python Pickle Format | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google BigQuery | read_gbq | to_gbq |